讨论一个大家都关注的SEO话题,搜索引擎如何识
这个话题是前段时间有个朋友问我的问题,正好给大家解释下。理解和运用到位的话最直接的作用就是可以不用担心抄袭所带来的SEO负面影响。这个话题虽然附子老师没有在SEO培训课程里面讲到,但是这次我分享出来给大家学习下。关于采集这个话题大家都应该知道,包括不少人也羡慕有些网站采集排名一直非常好,而自己做原创反倒没啥用,这里就有一个问题,为什么别人采集没啥问题,你采集就容易出问题,如果是新站SEO优化的时候,如果让百度不认为网站是采集而是转载。对于百度来说,内容的传播分为价值和无价值,而把这个点学透的话,自然就可以理解到采集和非采集的真谛,从而SEO采集内容会效果好很多。
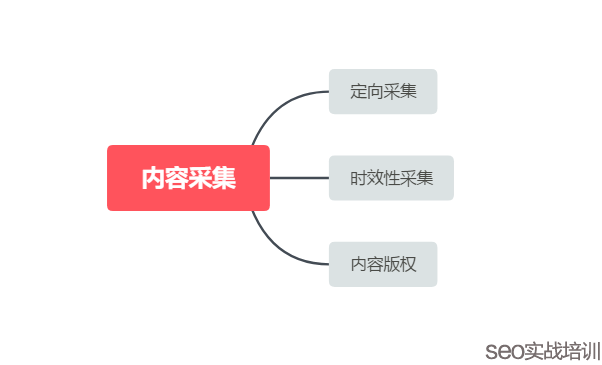
关于内容采集从搜索引擎角度来说的话,基本上需要做上面这个三点才能做好转载这个点。比如我们常见的内容采集是提取网页主体内容,然后有些连图片,排版什么都乱七八糟的,这种内容肯定容易出问题。那么附子老师举个例子,比如我们做了一篇内容,被新浪转载了,新浪很显然是不可能认为采集而是转载的。虽然我上面讲到一点就是内容版权,对于百度官方白皮书来说也明确说过了转载一定要带内容版权,否则容易成为无价值的垃圾内容。
百度站长平台原文:https://ziyuan.baidu.com/college/courseinfo?id=1337
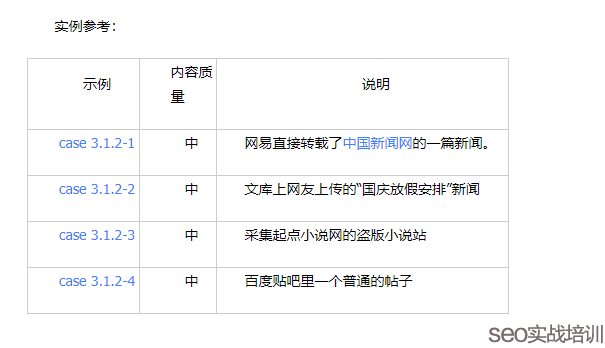

这里百度说明的很明确,一个是采集内容书属于质量中等,但是下面又写了一段,别处采集的内容未经最起码的编辑,这个就是采集和转载的答案区别。对于新站来说,这里附子老师教大家一招,内容采集的时候,新站带好来源版权,给来源做锚文本链接,让搜索引擎完全识别内容的出处,这样的话及时你采集也容易被认为是转载。
对于老站来说,你去采集可以不带锚文本,但是最好带上来源。不管是新站还是老站,采集过后的内容一定不要所有内容都采集,要选择性的采集,也就是我上面讲的定向采集,针对性的采集一些有价值的。因为很多时候原文都不一定有价值,你采集过来反倒质量更差,比如一些内容空缺的内容页面,口水话的内容页面等。
